Observability is not an afterthought in this homelab — it’s a first-class concern. Every workload is monitored, every log line is indexed, and every alert has a defined routing policy. The stack is designed to answer three questions: What is the system doing right now? What happened in the past? What should I be notified about?
The stack runs entirely in the monitoring namespace and is composed of well-established open-source projects, deployed via Helm.
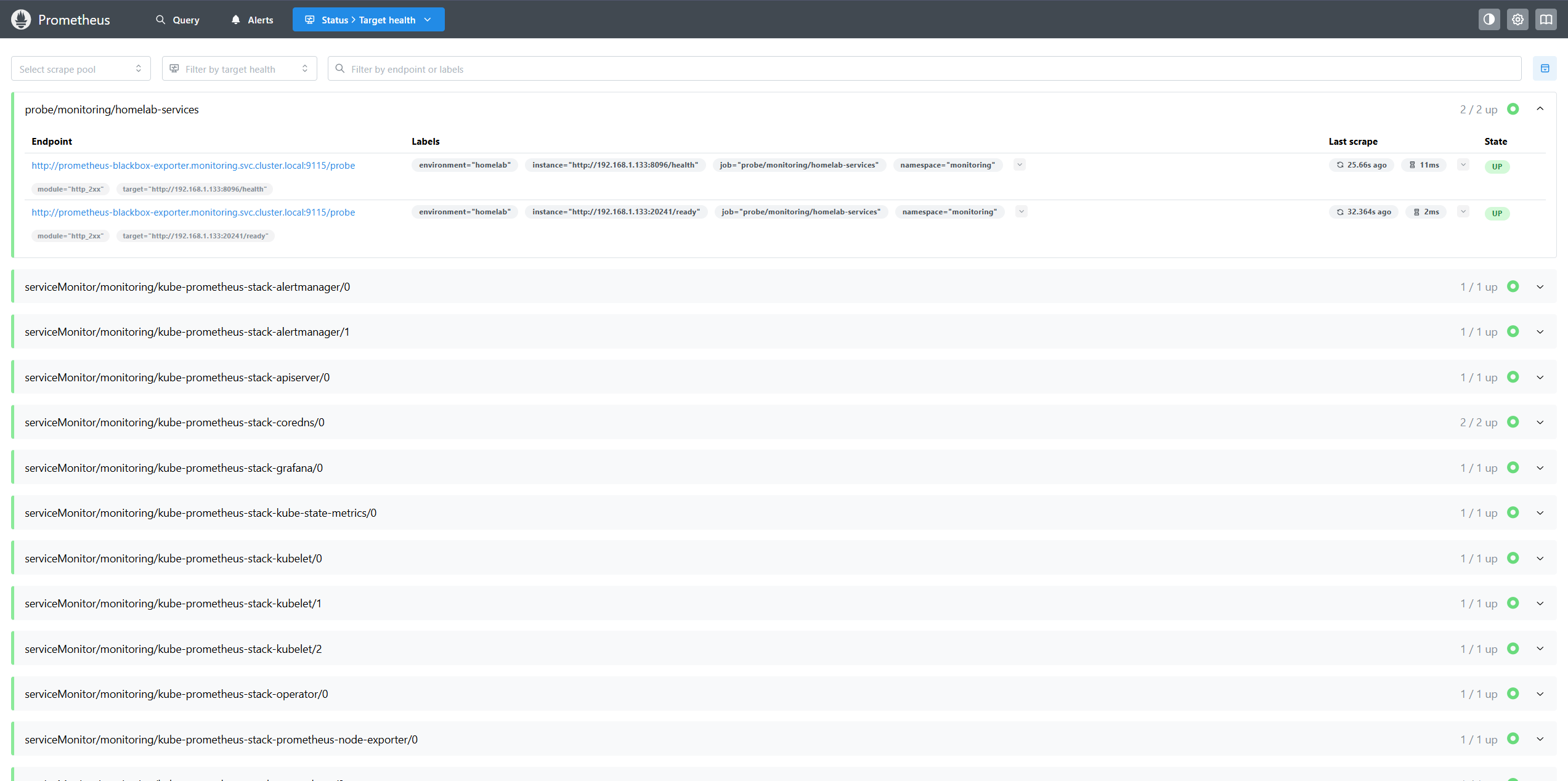
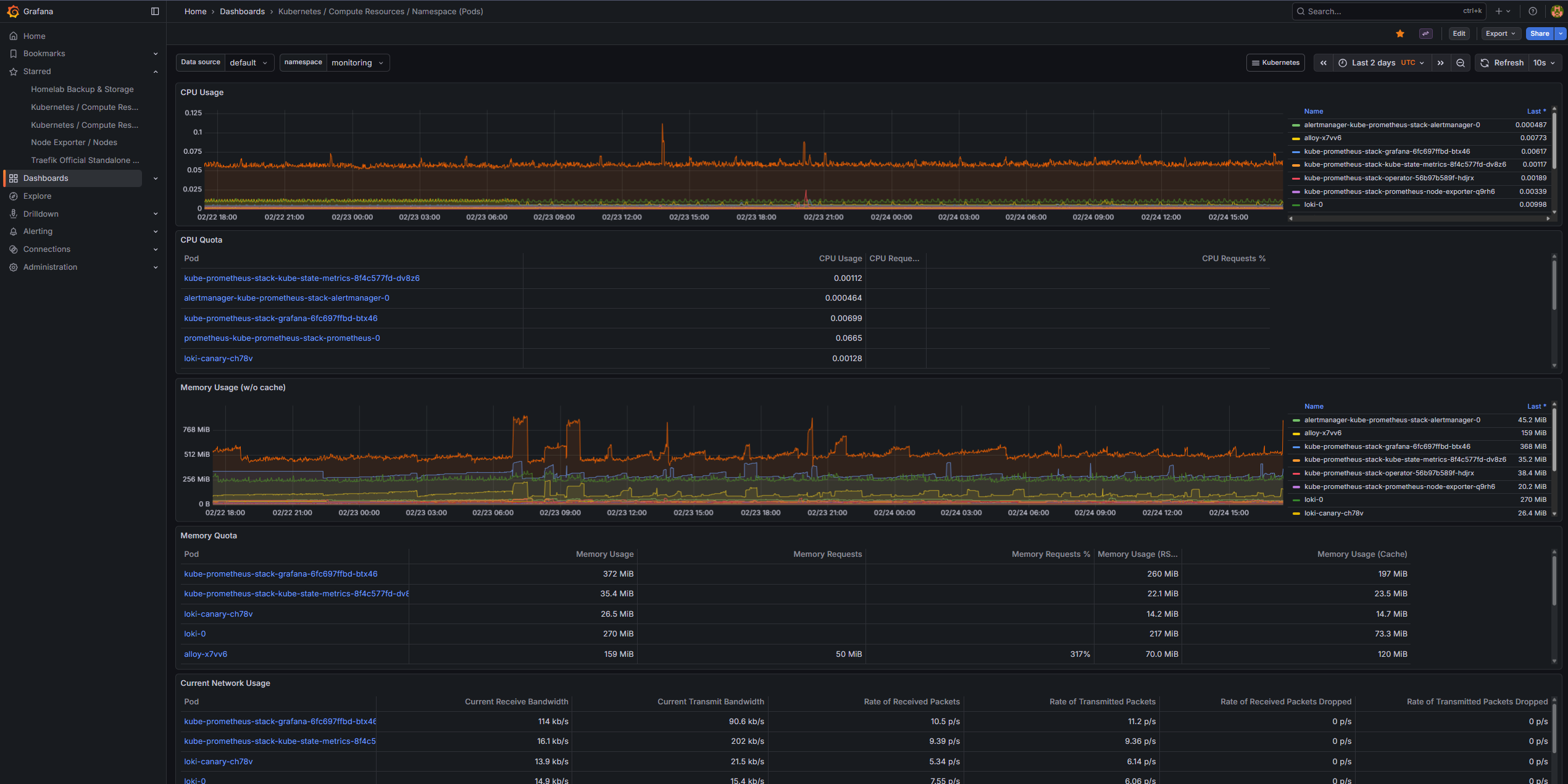
Prometheus is the time-series metrics database at the heart of the stack. It scrapes metrics from all configured targets on a pull model and stores them with a 5-day retention window in a 10 GiB PVC backed by local-path storage.
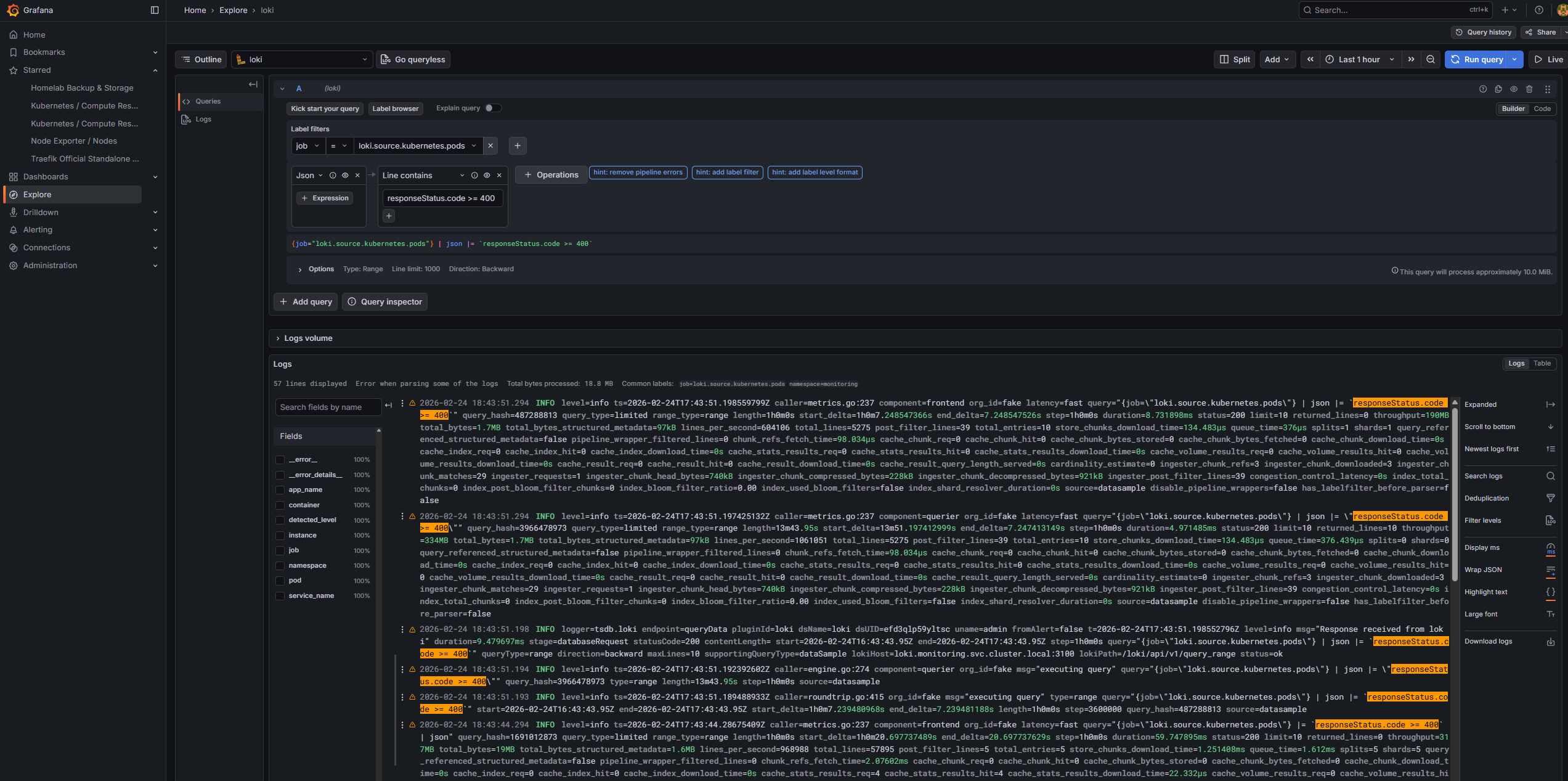
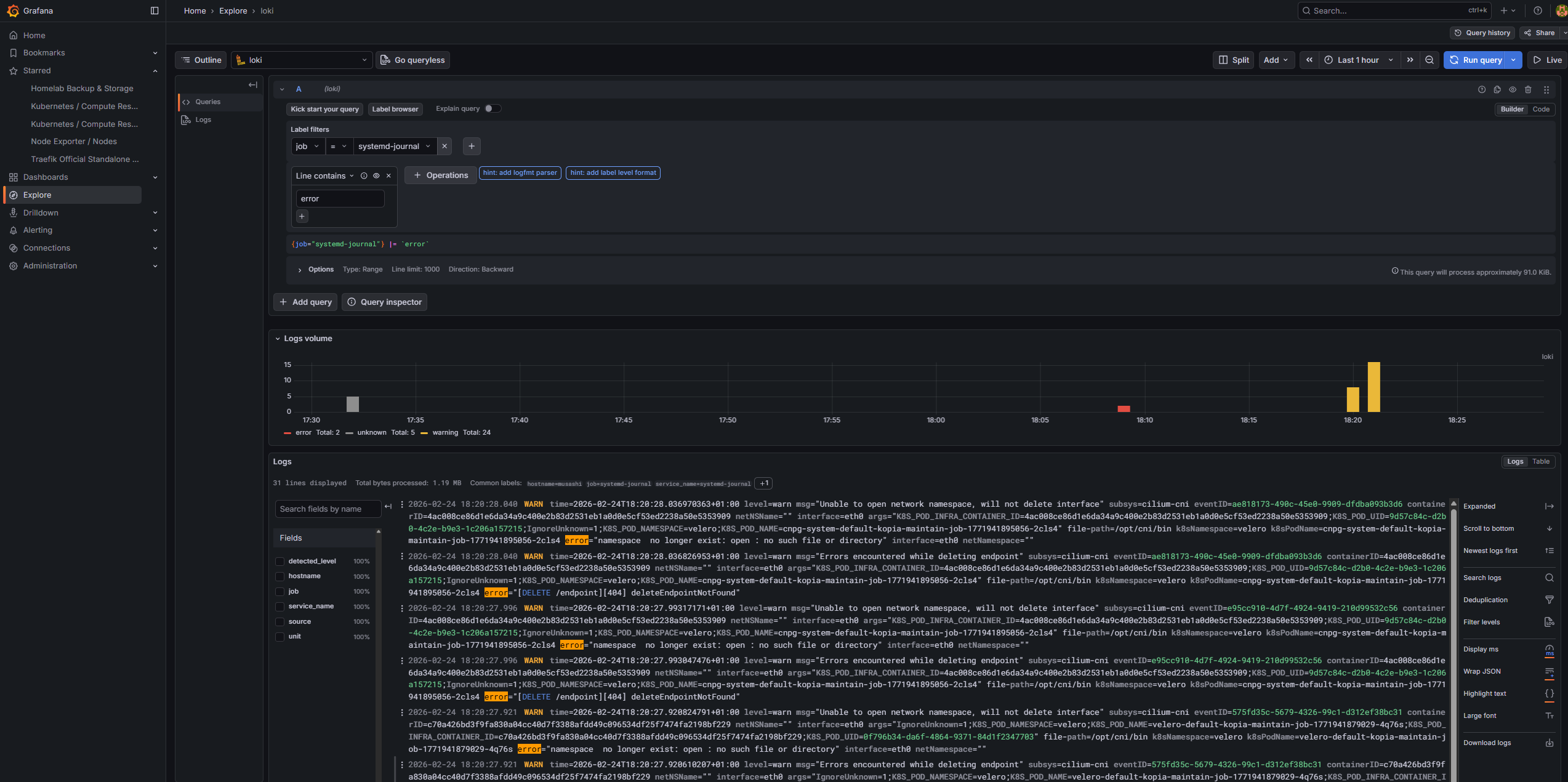
Log aggregation is handled by the Loki + Alloy combination. Loki stores logs in a compact, indexed format queryable with LogQL. Alloy is the modern replacement for Promtail — a fully programmable pipeline agent.
Alloy runs as a DaemonSet ensuring it’s present on every node. The loki-canary DaemonSet is a companion service that continuously writes test log entries to Loki and verifies they can be read back — providing a live health check of the log ingestion pipeline.
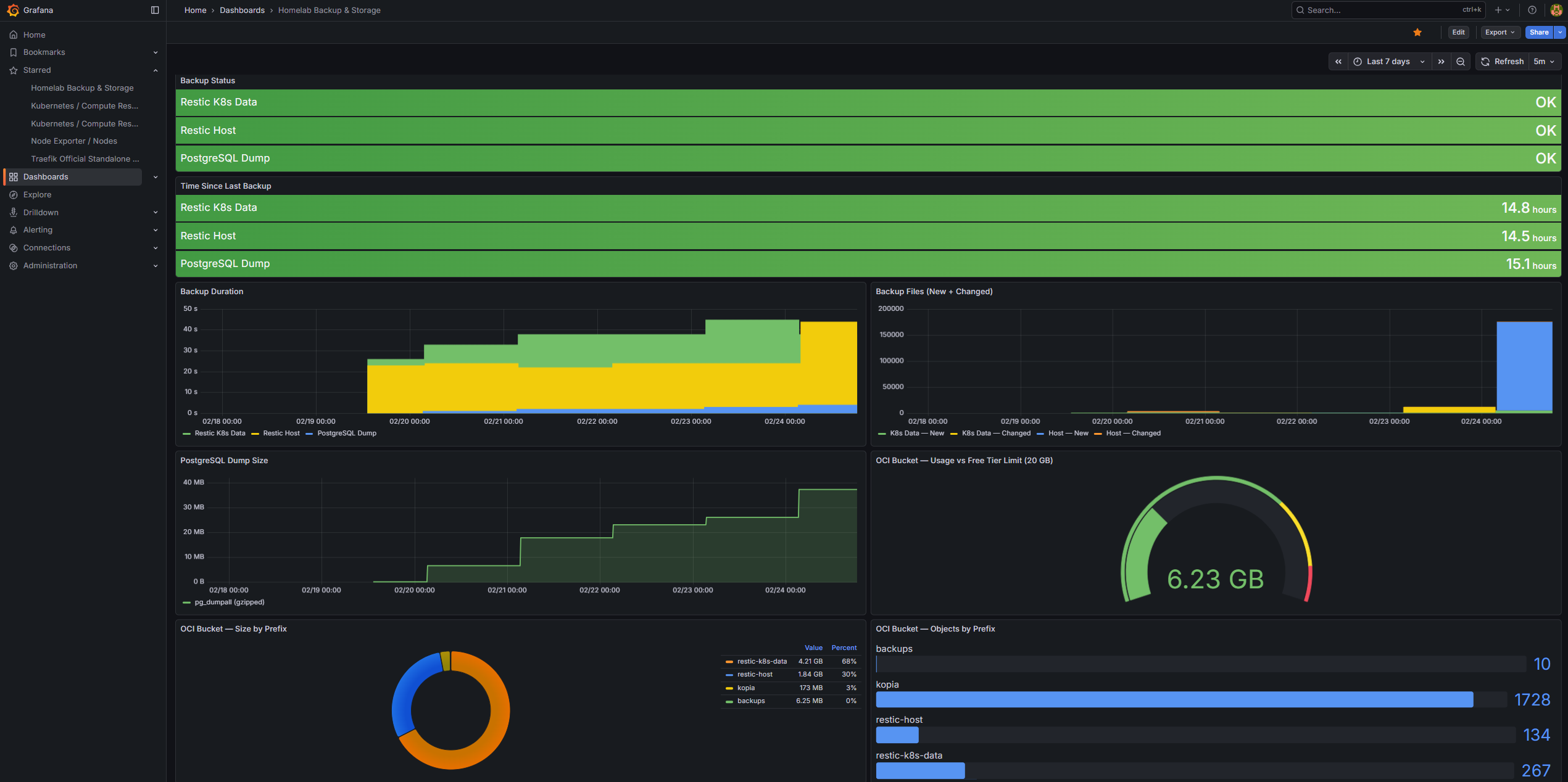
A fully custom dashboard tracks the backup and storage posture of the cluster. It ingests metrics pushed to Pushgateway by all four backup layers — Velero + Kopia, restic PVC data, pg_dumpall, and host configuration — and surfaces backup status, duration trends, PostgreSQL dump size over time, and OCI Object Storage usage against the 20 GB free tier limit.
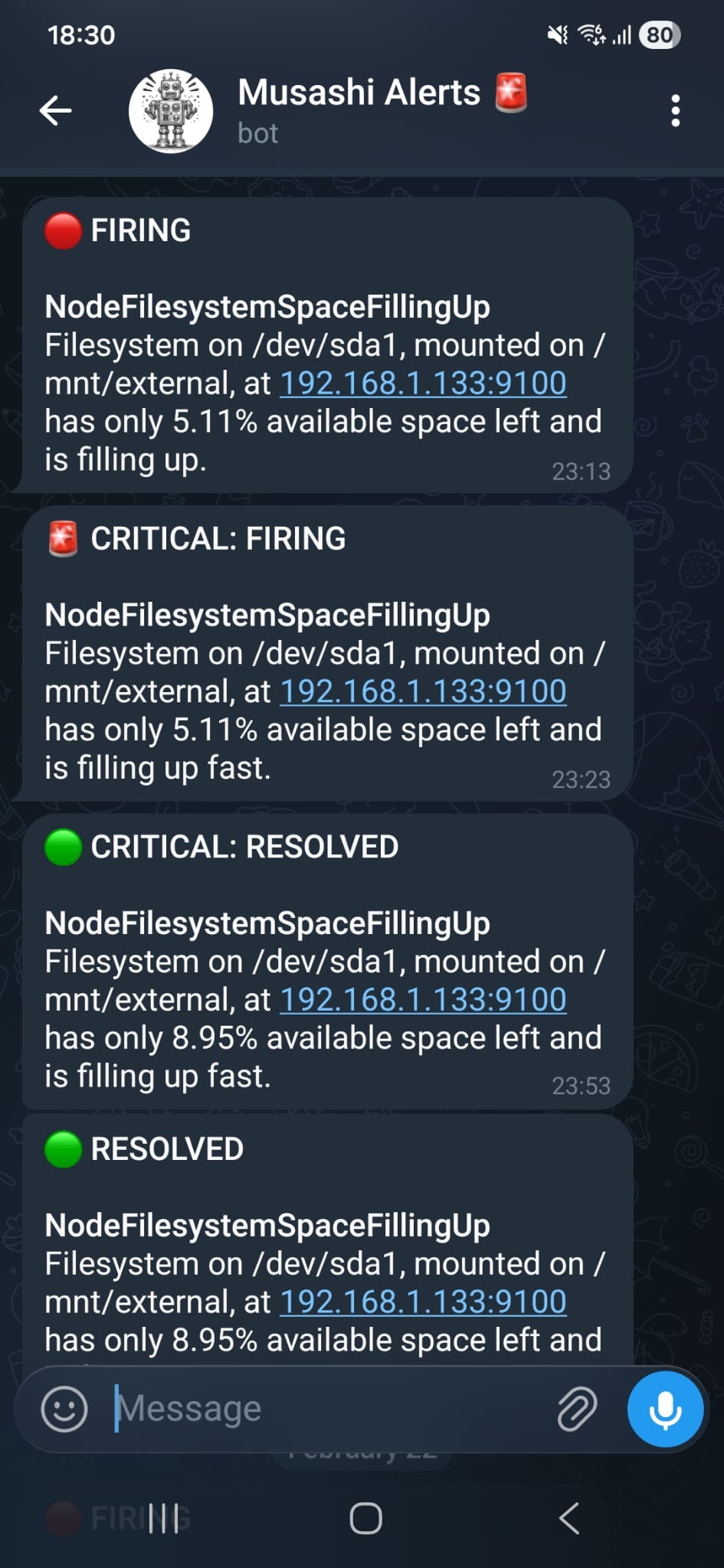
Critical alerts are sent immediately to both a Telegram bot (musashi_homelab_bot) and a Gmail address. The dual-channel approach ensures notifications are received even if one channel is unavailable.
The observability stack doesn’t just monitor — it actively gates deployments. During every canary rollout of Backstage, Argo Rollouts queries Prometheus for real-time application health metrics derived from Traefik’s ServiceMonitor:
Canary deployment starts
│
▼
Argo Rollouts creates AnalysisRun
│
▼ (every 30s)
Prometheus queries:
┌──────────────────────────────────────────────┐
│ error-rate: │
│ traefik_service_requests_total{code="5xx"} │
│ ÷ traefik_service_requests_total │
│ → must be ≤ 0.25 │
│ │
│ p95-latency: │
│ histogram_quantile(0.95, │
│ traefik_service_request_duration_bucket) │
│ → must be ≤ 5s │
│ │
│ pod-restarts: │
│ kube_pod_container_status_restarts_total │
│ → must be < 2 │
└──────────────────────────────────────────────┘
│
▼
Pass: continue canary → 100% promotion
Fail: automatic rollback to stable version
This turns Prometheus from a passive observer into an active safety gate, automatically protecting production from bad deployments.